MySQL全文索引
全文索引
除了普通索引,mysql也支持全文索引。
创建全文索引
普通索引使用字段的值作为索引,而搜索引擎的索引是基于关键词的,因此首先要分词。
对于英文,单词之间具有明显的分隔符(比如空格,逗号),分词很容易。但是对于象形字,比如中文、韩文,分词则很困难,不同的分词算法对搜索结果的影响很大。针对中日韩文,Mysql提供了一个简单的分词工具——ngram。ngram采用了最简单的分词算法,它将一个句子分成固定字数的短语,比如默认情况下,ngram_token_size的值为2,“我爱编程”会被分成“我爱”,“爱编”,“编程”。
从MySQL 5.7.6开始,ngram作为mysql自带的插件,可以直接使用。
在title字段上使用ngram分词器创建全文索引(用时11min):
CREATE FULLTEXT INDEX ft_index ON article1000(title) WITH PARSER ngram;
这段时间,mysqld占用的CPU接近100%。
通过match...again使用全文索引查询,以下sql查询titile中包含库里的记录,相当于执行select * from article1000 where title like '%库里%’:
select * from article1000
where match(title) AGAINST ('库里' IN NATURAL LANGUAGE MODE);
性能
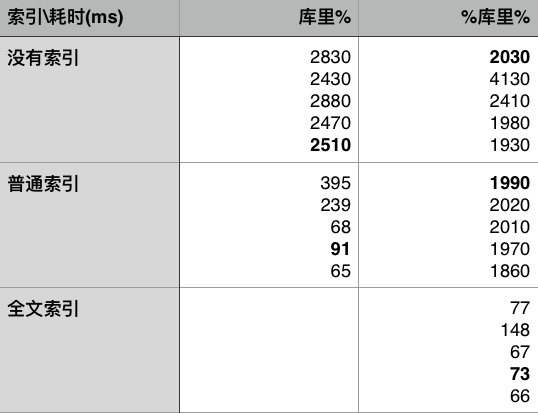
下表列出了没有使用索引,使用普通索引和全文索引查询标题中包含关键词库里的耗时对比,每次查询执行了5遍,每组数据的中位数使用粗体标出来。
全文搜索和相关度
前面的示例都比较简单,搜索字符串(search string)只包含一个关键词,数据库中的行在不在最终的结果里就看包不包含这个关键词。 一个真正的搜索引擎的搜索字符串常常是复杂的自然语言文本,这种自然语言全文搜索(natural-language full-text searches)是搜索引擎区别于数据库的最大不同。
下面的sql对标题搜索我喜欢你,标题不一定要完整的包含“我喜欢你”这几个字,只要包含“我喜”,“喜欢”,“欢你”,都会命中,只不过相关度不同而已。
select * from article1000
where match(title) AGAINST ('我喜欢你' IN NATURAL LANGUAGE MODE);
上面的结果是按相关度由高到低排序的,相关度是由TF-IDF算法计算的。通常结合limit和offset分页显示搜索结果。
下面的sql语句可以显示出每个结果的相关度。虽然在select和where包含了了两次match,但mysql优化器只会进行一次搜索,所以不会有而外的开销。
SELECT id, title, MATCH (title) AGAINST
('我喜欢你' IN NATURAL LANGUAGE MODE) AS score
FROM article1000 WHERE MATCH (title) AGAINST
('我喜欢你' IN NATURAL LANGUAGE MODE);
比如,结果中的我喜欢你,是因为我喜欢喜欢你的自己对应的score是29.815460205078125,我不喜欢这世界 只喜欢你的score是15.288071632385254。
全文搜索有三种模式,前面用到了的是NATURAL LANGUAGE MODE,除此之外还有BOOLEAN MODE和QUERY EXPANSION两种,具体用法请参考mysql manual。
下面是一个比较复杂的示例,查询标题中同时包含詹姆斯和克利夫兰的文档,数据结果按照发布时间倒序排序:
SELECT * from article1000 where match(title) AGAINST (‘+"詹姆斯" +"克利夫兰"' IN BOOLEAN MODE) order by publish_time DESC;
其中,+表示必须包含某个关键词,对应的,-表示不能包含。"扩起来的字符串表示精确匹配,不分词。
教程 2020-08-21 10:46:12 通过 网页 浏览(325)
共有0条评论!